Hi folks! In this post I'm doing a summary of Beam Search so I can understand it better and hopefully help someone :)
Beam search is a heuristic algorithm used in sequence models for tasks like translation, text generation, and voice recognition. It is an improvement over breadth-first search.
How it works?
At each step of the process, beam search keeps a limited set of sequences that seem promising given a score or probability.
This set is called the beam and its size is controlled by a parameter called beam width, usually represented by the character K.
Steps to create a sequence
- We start with the initial state, which could be <start> or the tag that you are using.
- Expansion: Generate all possible words or tokens given the current sequences. At the starting point, it is <start> + all the tokens in the vocabulary.
- Selection: Get a score for each extended sequence and pick the K best.
- Repeat: Repeat the process until you reach <stop> or a "stop" token you define.
Whiteboard explanation
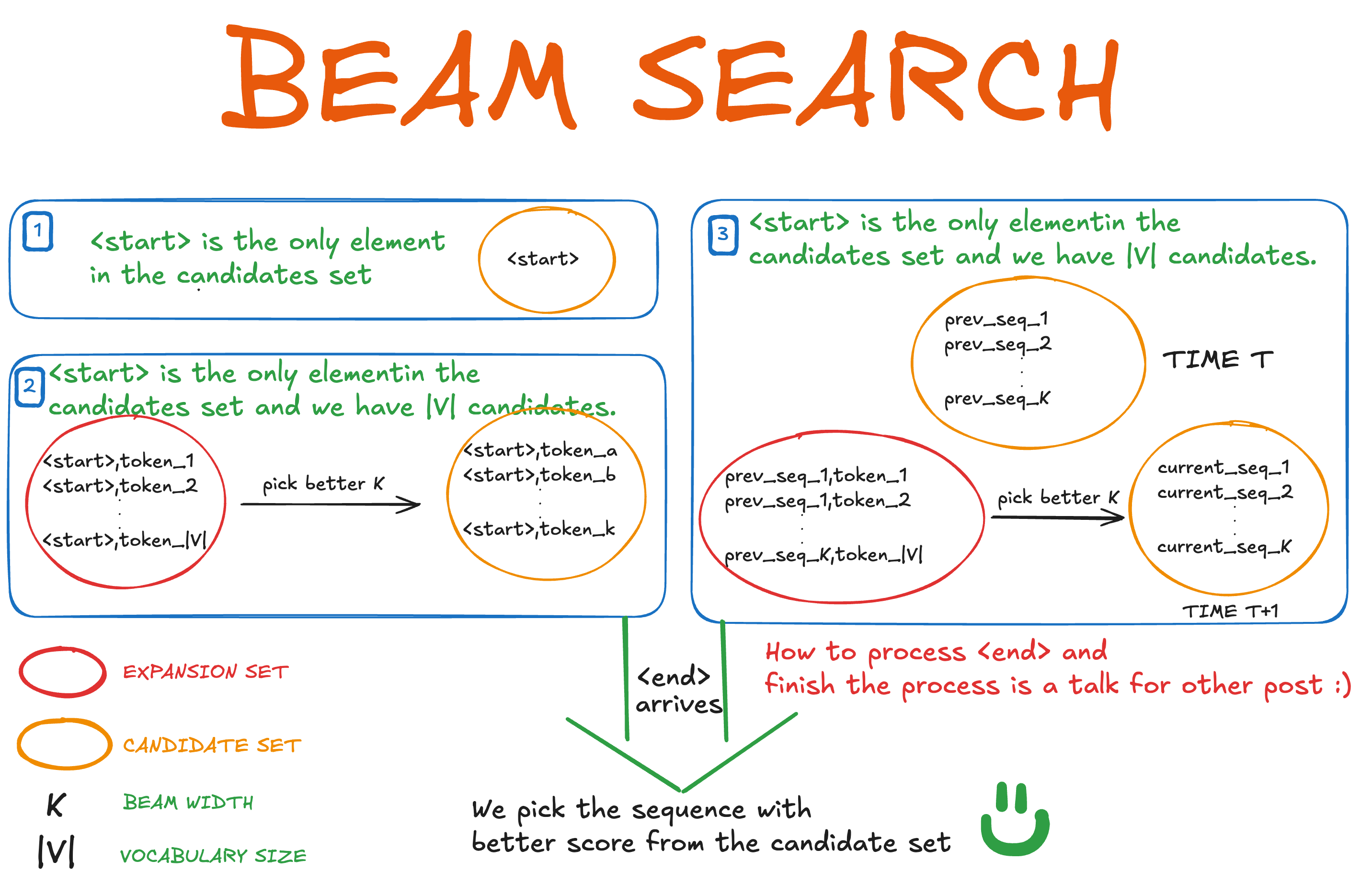
In other words 👨🏻💼:
Let's say we have the following set at a given time t, and let's call that set C for candidates.
At time t+1 we have \(\tilde{C} _{t+1}\) which expands \(C_t\):
This gives us a set of size: K*|V|, where |V| is the size of the vocabulary; here we need to pick again the best K candidates. In seq2seq architectures the size is usually K*K, but it depends on the implementation.
Benefits
- Balance between exploration and efficiency: Does not explore all options, but is better than greedy search.
- Precision: Usually gets better sequences than other simpler strategies.
Cons
- Does not guarantee a global optimum.
- Computationally Expensive: Requires more calculations than simpler strategies.